关于我 · 技术面
企业级后端、架构、云原生、AI 工程化。

履历时间轴
2026
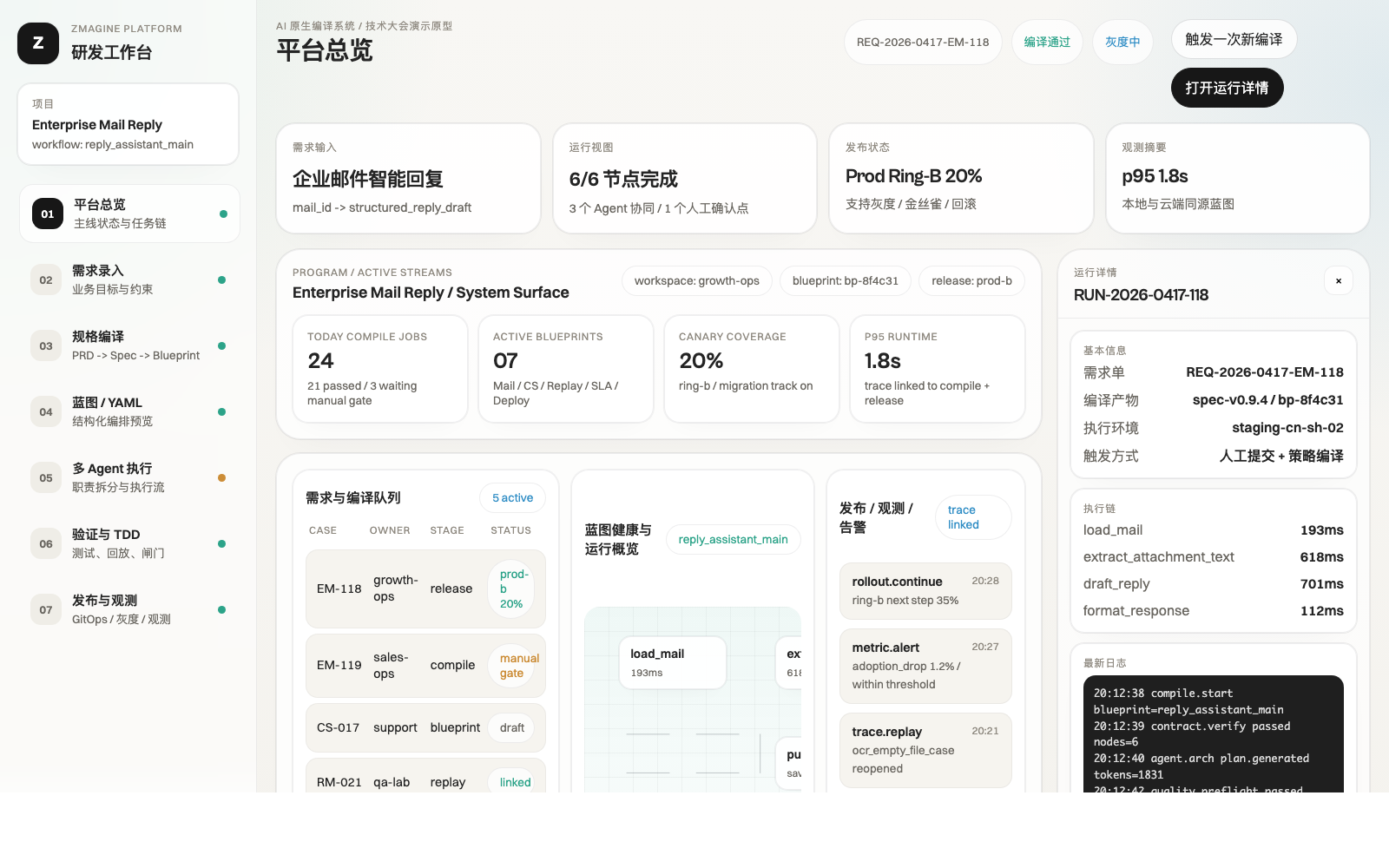
创办 Zmagine研发企业 AI 应用的大脑平台 / 新媒体影响力建设
2024
字节跳动 · 后端技术负责人AI 工程化实践 Top 1% 纪录保持者
2022
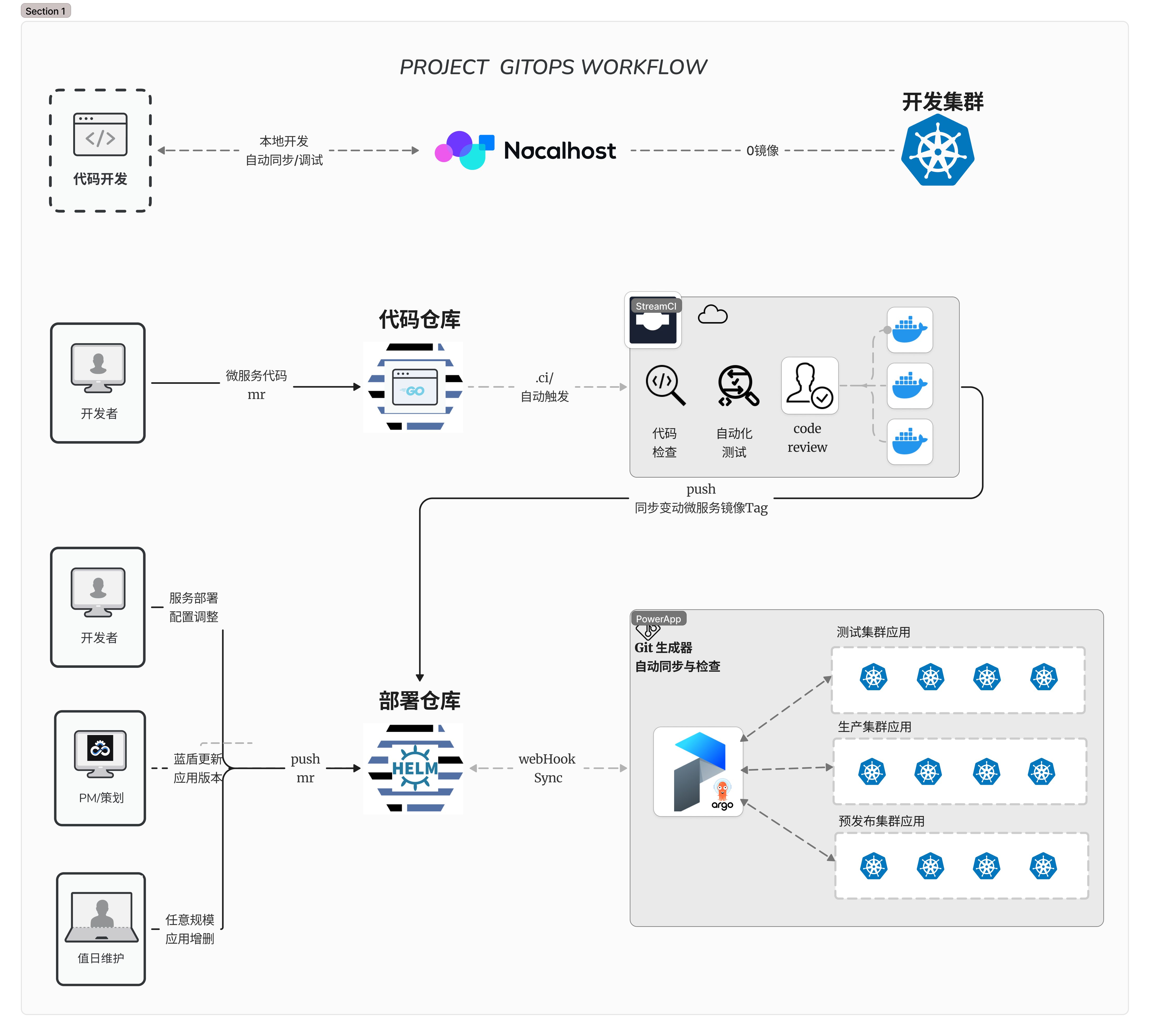
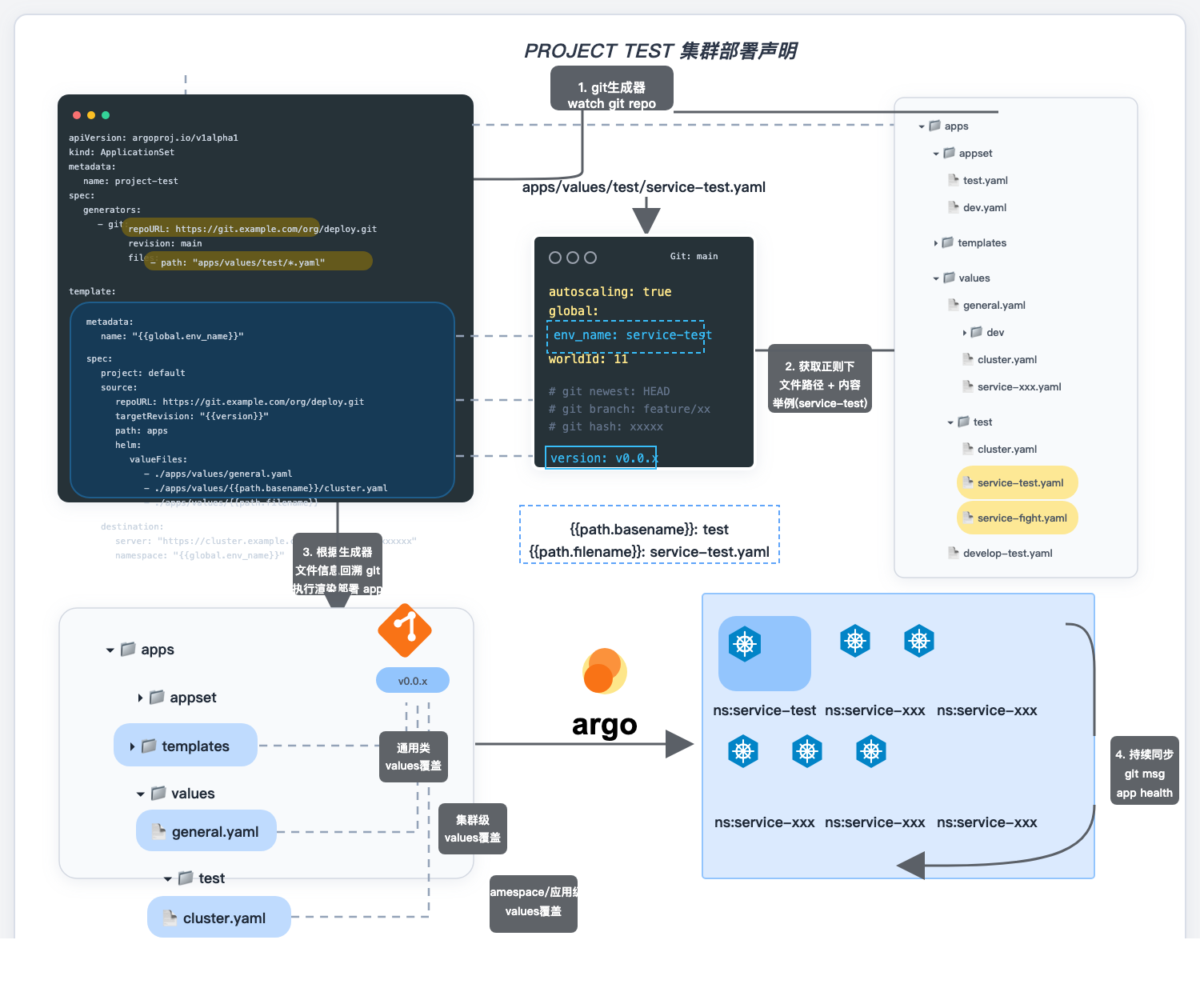
腾讯游戏 · 云原生架构师主导腾讯游戏上云自动化交付体系
2021
InfoQ 编辑推荐 / 极客时间签约讲师限流、云原生、Go 语言课程与工程实践输出
2020
网易游戏 · 高级后端研发梦幻西游
2019
YY 语音 · 后端研发基础架构部
从基础设施、游戏业务到企业 AI 平台,我长期处理的都是复杂系统如何稳定落地。